Stable Diffusion 3 es la nueva generación de IA de texto a imagen de Stability AI, la empresa que revolucionó la creación visual al compartir el primer modelo de código abierto para la generación de imágenes mediante Inteligencia Artificial
Elanuncio de esta tercera seguido unos días más tarde por la publicación de los Research Papers.
El modelo se ha compartido públicamente en una versión ligera denominada SD3 Medium ,y también puede utilizarse una versión más potente con la API Stability AI
🗞️
Stable Diffusion 3.0 Medium está disponible - 12/06/2024
Ya puede descargarse de HuggingFace y utilizarse libremente en licencia no comerciales
Los diseñadores y las empresas que generen menos de un millón de dólares de ingresos anuales pueden acceder gratuitamente a una licencia comunitaria.
¿Qué es la Stable Diffusion 3?
Stable Diffusion 3 es la nueva generación de modelos de IA de texto-imagen publicada por Stability AI.
Para que te hagas una idea, el modelo más pequeño es algo inferior al tamaño del Stable Diffusion 1.5 (1B), mientras que el modelo más grande es ligeramente superior al Stable Diffusion XL (6,6B para la base + refinador).
Este diseño familiar de modelos de tamaño variable sigue la tendencia iniciada por la mayoría de los principales modelos lingüísticos (IA generativa de texto): Google, Meta y Mistral han publicado modelos básicos de distintos tamaños, adaptados a diferentes casos de uso.
La nueva Stable Diffusion
El año 2023 marcó un hito para la inteligencia artificial de código abierto con Stable Diffusion como el mejor ejemplo de IA totalmente abierta. Hemos visto avances significativos con SDXL innumerables ajustes y modificaciones para crear imágenes y vídeos asombrosamente realistas
El paso a Stable Diffusion 3 ofrece una gran cantidad de mejoras y es probablemente la actualización más importante jamás vista para Stable Diffusion. Esta nueva versión pretende mejorar el rendimiento en GPU más pequeñas al tiempo que reivindica mayores capacidades, incluida la gestión de imágenes, vídeo y 3D
Stable Diffusion 3 se entrena con entre 800 millones y 8.000 millones de parámetros, lo que ofrece una amplia gama de modelos para satisfacer las necesidades creativas en función de la capacidad de la GPU. Combina una arquitectura de Transformador de difusión y Stream Matching, un avance técnico significativo. Esta actualización también hace hincapié en las prácticas seguras y responsables de la IA para evitar su uso indebido.
La llegada de Stable Diffusion 3, con sus numerosas mejoras como el procesamiento de texto y su capacidad para manejar entradas multimodales, podría marcar uno de los lanzamientos más significativos de 2024, posiblemente superando a Gemini (Google) y Sora (OpenAI).
Stability AI promete tambien integrar capacidades de vídeo y 3D en un único modelo, una primicia en este campo
Mejoras y puntos fuertes
En 𝕏, varios miembros del equipo de Stability han compartido imágenes generadas mediante Stable Diffusion 3 que muestran una mejora de la calidad, sobre todo en la finura de los detalles. La inteligencia artificial es capaz incluso de escribir frases completas, una tarea habitualmente difícil para los modelos de generación de imágenes.
Textos específicos
Uno de los principales puntos débiles de las versiones anteriores era la generación de texto. Stable Diffusion 1.5 era muy malo en este aspecto. SDXL es un poco mejor, pero sigue teniendo problemas para escribir más de una palabra, y con qué regularidad se cometen errores.
Más recientemente, Stable Cascade, otro modelo creado por Stability AI, ha mostrado algunas mejoras interesantes. Pero sigue siendo muy aleatorio, y las frases largas son sencillamente imposibles de obtener.
Pero todo eso va a cambiar con Stable Diffusion 3, que presume de mejorado la ortografía y la coherencia del texto, y será considerablemente más fiable para tareas como la redacción de pies de foto y la creación de logotipos
Los ejemplos compartidos por Stability AI y su equipo incluyen un gran número de imágenes con uno o más fragmentos de texto que tienen un aspecto excelente, ¡incluidos textos más largos que simples palabras!
Mejor cumplimiento de las instrucciones
Prompt : Photo of a red sphere on top of a blue cube. Behind them is a green triangle, on the right is a dog, on the left is a cat
Uno de los puntos débiles de SDXL y Stable Cascade es que no siguen indicaciones e instrucciones complejas tan bien como DALL-E 3.
Una de las innovaciones de DALL-E 3 fue el uso de subtítulos de imágenes muy precisos a la hora de entrenar al modelo, con el fin de enseñarle a seguir correctamente indicaciones complejas. Ahora parece que Stability AI se ha inspirado en este método para mejorar Stable Diffusion.
Por lo tanto, Stable Diffusion 3 debería ser al menos tan bueno como DALLE 3 a la hora de seguir las instrucciones.
Rapidez y facilidad de despliegue
Uno de los objetivos de Stability AI es hacer accesible la IA generativa compartiendo modelos que puedan utilizarse en ordenadores domésticos.
Las pruebas iniciales sugieren que se podrá ejecutar localmente la versión más grande de Stable Diffusion 3 utilizando una tarjeta de vídeo con 24 GB de RAM. Este requisito probablemente se reducirá después del lanzamiento, cuando la comunidad empiece a probar y ajustar todo tipo de optimizaciones en los PC de consumo.
El valor de referencia inicial es de 34 segundos para una imagen de 1024×1024 en la tarjeta de vídeo RTX 4090 (50 pasos). También en este caso podemos esperar lógicamente un gran progreso en las semanas siguientes al lanzamiento de Stable Diffusion 3.
3D y generación de vídeo
Prompt: Photo of an 90's desktop computer on a work desk, on the computer screen it says "welcome". On the wall in the background we see beautiful graffiti with the text "SD3" very large on the wall.
Aunque Syable Diffusion 3 aún está en fase de desarrollo - con solo su version Medium publicada, Stability AI está explorando el uso de Diffusion 3 estable para generar imágenes en 3D e incluso vídeos sin duda abrirá interesantes posibilidades para futuras aplicaciones
Seguridad
En función de la evolución del sector de la IA generativa y de las buenas prácticas que se pongan en marcha, es muy probable que Stable Diffusion 3 se diseñe para generar únicamente imágenes SFW (Safe for Work) como ya ocurre con Stable Cascade
Stability AI ha puesto en marcha un sistema que permite a los artistas que no deseen que su obra aparezca en la no participar, por lo que Stable Diffusion 3 debería tener menos probabilidades de ser utilizada indebidamente y de infringir los derechos de autor, aunque esto puede reducir la variedad de estilos disponibles
Cookie Monster testifying before the International Court of Justice in The Hague
Cambios y novedades
Nueva arquitectura
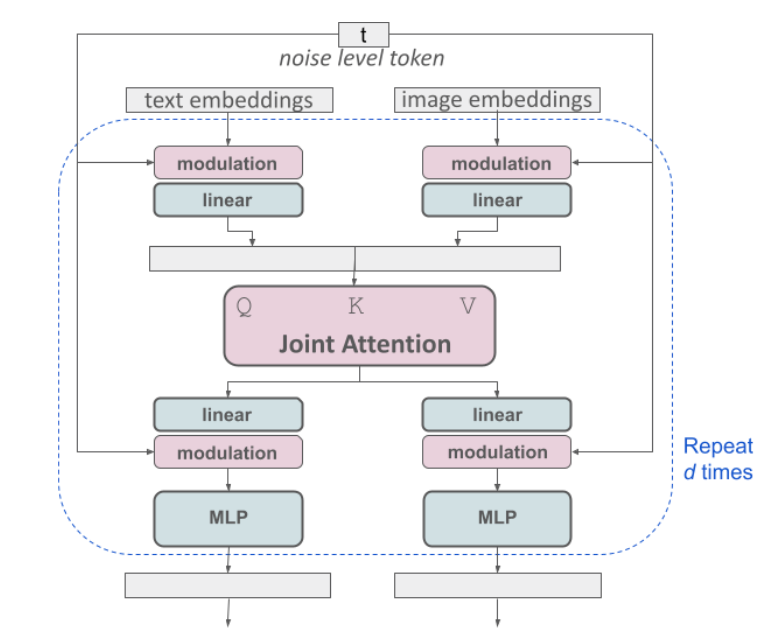
3.0 utiliza una arquitectura transformadores de difusión cambio significativo respecto a Stable Diffusion 1 y 2, que utilizaban una arquitectura basada en la U-Net utilizada en Stable Diffusion 1 y 2
Una de las ventajas de esta técnica, tomada de los modelos lingüísticos, es que permite una mejora previsible del rendimiento a medida que aumenta el tamaño del modelo. Este nuevo enfoque también ayuda a mejorar la calidad de la imagen, el rendimiento y la comprensión del texto
Además, la nueva arquitectura está diseñada para ser multimodal, separando las ponderaciones de las representaciones de la imagen y del lenguaje y garantizando al mismo tiempo un vínculo coherente entre ambas.
Otro de los avances de SD3 es el uso del muestreo de flujo rectificado (RF): esta innovación permite rutas de inferencia más directas y reduce el número de pasos necesarios para generar imágenes, manteniendo o mejorando el rendimiento.
Tres codificadores de texto
Stable Diffusion 1 utilizaba un único codificador de texto (CLIP).
A continuación, Stable Diffusion XL innovó utilizando dos codificadores (CLIP y OpenCLIP).
Stable Diffusion 3 va incluso más allá y utilizará hasta tres codificadores: CLIP L/14 (OpenAI), OpenCLIP bigG/14 y T5-v1.1-XXL. Sin embargo, el tercer codificador (T5) es bastante grande y puede eliminarse sin pérdida de calidad para las generaciones que no incluyan texto.
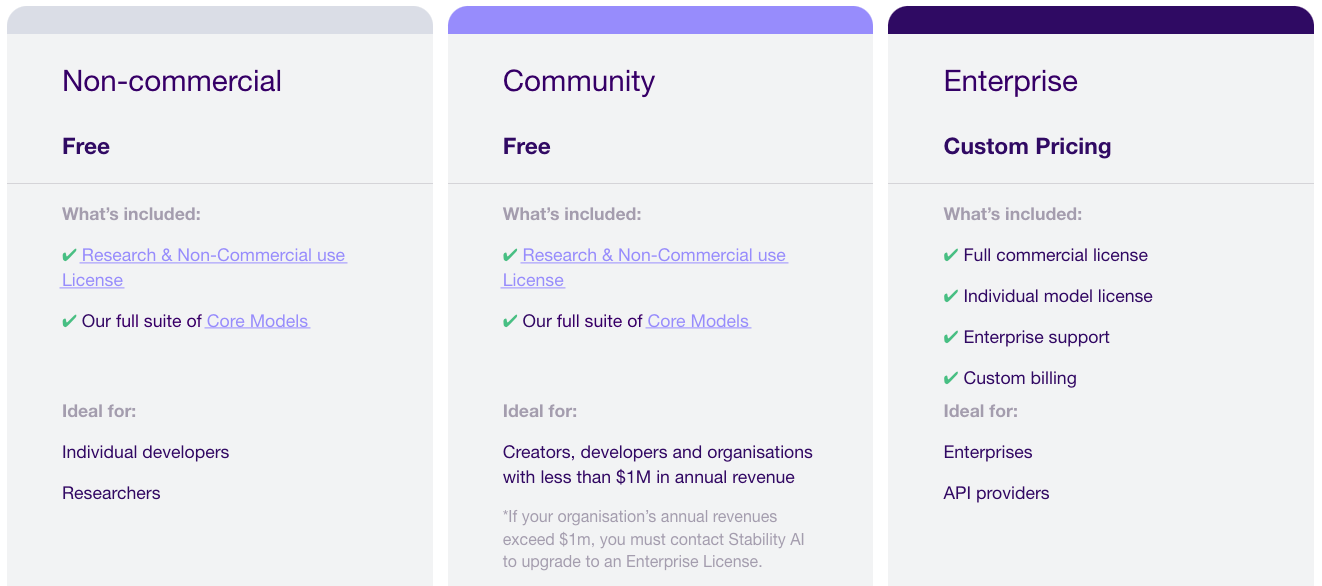
Estabilidad AI Licencias
Aunque (algunos) modelos de Stable Diffusion 3 se comparten libremente y se pueden descargar, su uso comercial no es necesariamente gratuito.
Stability AI, de hecho, comparte el modelo con 3 licencias diferentes: Non-Commercial (Gratuita) para investigación y desarrollo, Community (Gratuita) para creadores y uso comercial por empresas que ganen menos de 1 millón de dólares al año y Enterprise (de pago) para empresas que ganen más de 1 millón de dólares al año