
Table of Contents
- ¿Stable Diffusion = PC potente?
- Las ventajas de la nube Diffus
- Acceso simplificado
- Mantenimiento cero
- Numerosas ampliaciones
- Más de 13.000 modelos disponibles
- ¿Cómo se utiliza Diffus?
- Crear una cuenta
- Uso de SDXL en Diffus
- Añadir SDXL al workspace
- Creación de una imagen con SDXL
- Características del difusor
- Bibliotecas modelo
- Descargue sus propios modelos
- Utilización de modelos
- Galería de imágenes
- Detalles de la imagen
- Filtrar colecciones
- Modo Boost
- ¿Cómo se utiliza Boost?
- Créditos y suscripciones
- ¿Diffus es gratuito?
- Suscripciones Diffus
- Ventajas de la suscripción
- Gana 50 créditos extra al día
- No espere más, pruebe Diffus

Do not index
canonical-url
Publish
Publish
Flag
Diffus es un servicio en línea eficaz y asequible para utilizar Stable Diffusion -sin necesidad de una máquina potente ni nada que instalar- y basta con unos pocos clics para generar imágenes en menos de un minuto
Con Diffus, Graviti nos ofrece una plataforma en la nube para alojar la interfaz web de Stable Diffusion. Este servicio nos permite utilizar la interfaz directa y fácilmente para crear imágenes con IA sin ningún obstáculo técnico. Y como todo está en la nube, Diffus funciona desde cualquier ordenador, tableta o teléfono conectado a Internet.
Actualización 20/01/2024: Llegada de REFOCUS
¿Stable Diffusion = PC potente?
La primera limitación para utilizar Stable Diffusion es la potencia que requiere para funcionar. La IA necesita un ordenador robusto con una tarjeta gráfica de alto rendimiento generación de imágenes requiere una gran cantidad de recursos para funcionar y generar imágenes de alta calidad
Instalar el código del modelo y sus dependencias también puede ser una tarea tediosa y compleja para algunos usuarios, aunque hacemos todo lo posible por dejarlo lo más claro posible en nuestros tutoriales y guías de instalación.
La buena noticia es que existe una forma alternativa de ejecutar Stable Diffusion en la nube, sin necesidad de un PC potente ni de ninguna instalación adicional.
Se trata de Diffus, una plataforma web que ofrece acceso a Stable Diffusion a través de la conocida y fiable interfaz de usuario de Automatic1111, lo que convierte la creación de imágenes con Stable Diffusion en un juego de niños: unos pocos clics bastan para generar tus imágenes, descargarlas en tu ordenador o compartirlas en las redes sociales
Las ventajas de la nube Diffus
Acceso simplificado
Al ofrecer acceso directo a Stable Diffusion desde cualquier ordenador o dispositivo conectado a Internet, Diffus permite utilizar la IA sin complicaciones técnicas ni conocimientos previos.
Mantenimiento cero
Con el alojamiento en la nube, Diffus elimina la necesidad de gestionar la infraestructura subyacente: no sólo no hay nada que instalar, sino que siempre se beneficiará de las últimas versiones y tecnologías para la generación de imágenes con Stable Diffusion.
Numerosas ampliaciones
La interfaz Automatic1111 disponible en Diffus viene con una serie de plugins populares preinstalados: ControlNet, Roop, Adetailer, Infinite Zoom, 3D Openpose,...
Los equipos de Diffus se preocupan de incluir las mejores extensiones para que pueda utilizar las últimas técnicas de generación de imágenes y crear libremente con Stable Diffusion.

Más de 13.000 modelos disponibles
Con más de 13.000 plantillas, LoRA y extensiones, Diffus ofrece una amplia gama de opciones para crear y personalizar imágenes. Además de las plantillas estándar Stable Diffusion XL y SD 1.5, puedes utilizar prácticamente cualquier plantilla, punto de control o LoRA compartido en Civitai. Y por si fuera poco, también puedes descargar tus propias plantillas y utilizarlas en Diffus




¿Cómo se utiliza Diffus?
Crear una cuenta
Get Started.
Crea tu cuenta siguiendo las sencillas instrucciones de la página de inicio de sesión. También puedes iniciar sesión con un solo clic utilizando tu cuenta de Google o Github.
Una vez creada tu cuenta, Diffus abrirá la interfaz web de Stable Diffusion y podrás empezar a crear imágenes con ella.
Diffus funciona con la interfaz Automatic1111, cuyas funciones se describen detalladamente manual completo en espanol.
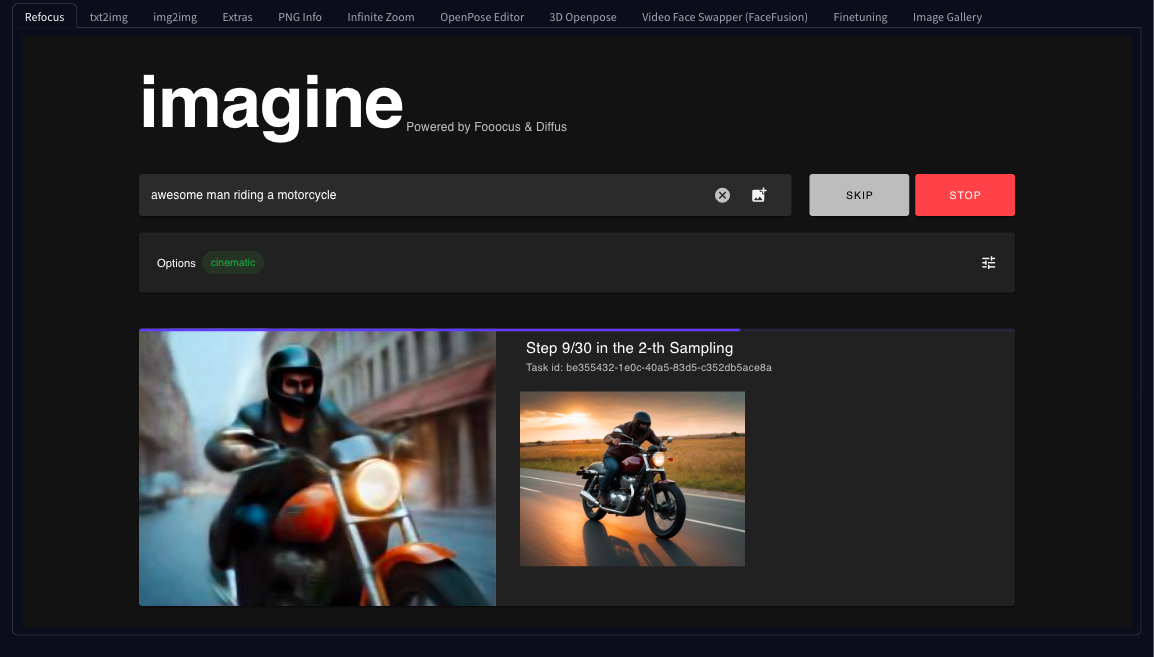
Pero para generar su primera imagen, todo lo que tiene que hacer es introducir una Prompt y hacer clic en el botón Generate: así de sencillo
Veamos ahora cómo configurar Diffus para utilizar Stable Diffusion XL y su refinador.
Uso de SDXL en Diffus
Añadir SDXL al workspace
Para evitar sobrecargar la interfaz con demasiadas modelos, Diffus utiliza un sistema de Workspace en el que puedes añadir los checkpoints, LoRAs y otras modelos a medida que quieras utilizar.
Para utilizar SDXL, tienes que añadirlo a tu Workspace cómo :
- Abra la biblioteca de modelos pulsando el botón Browse all Models parte superior derecha de la pantalla:

- Desplácese hasta la barra de búsqueda y la sección Models Galery.
- Escriba
SDXL_V10para iniciar la búsqueda y busque el modelo sdXL_v10VAEFix en los resultados
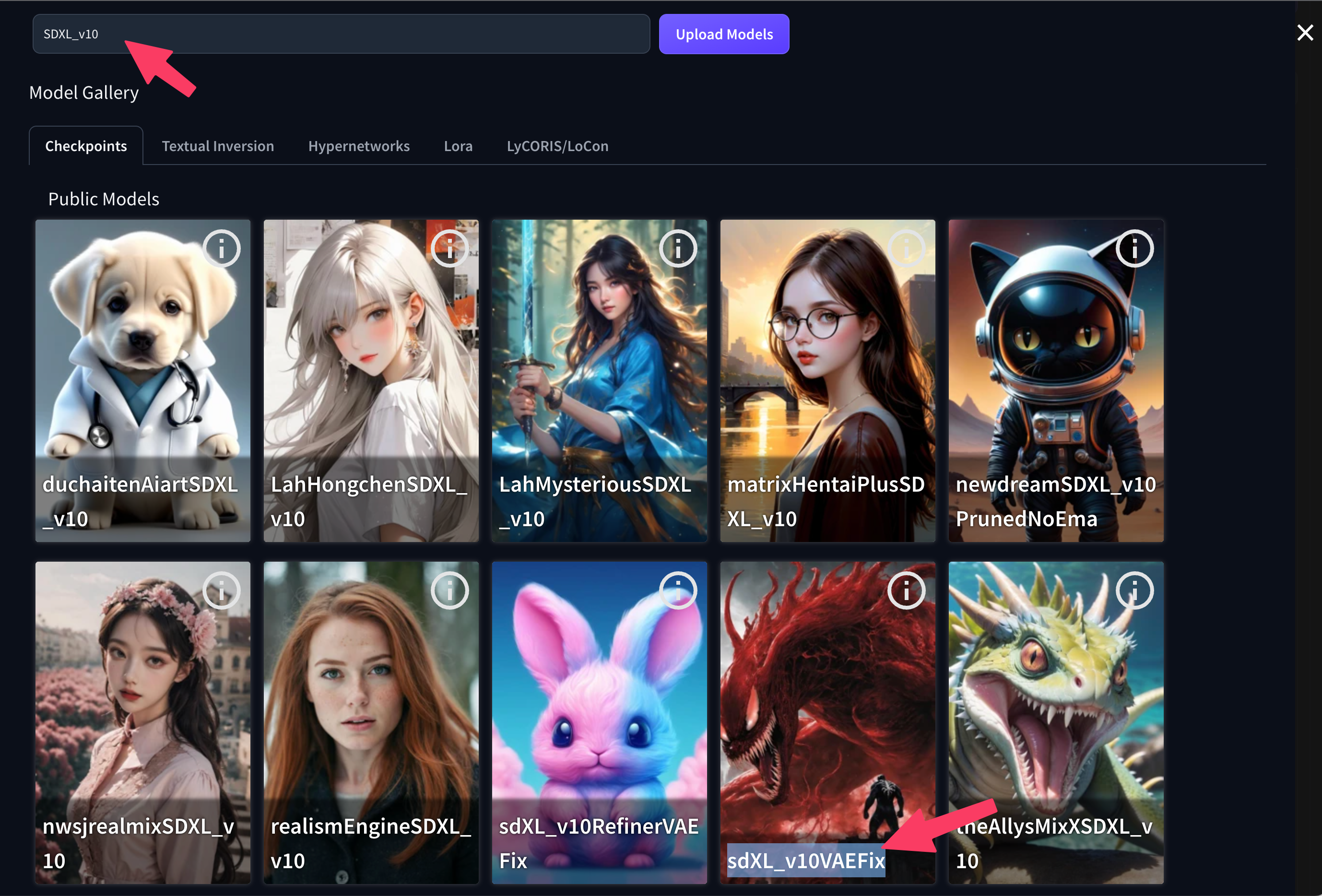
- Seleccione y añada el modelo haciendo clic en Añadir al espacio de trabajo (aparece al pasar el ratón por encima)
- Añade también el modelo sdXL_v10RefinerVAEFix : se trata del Refiner que acompaña al modelo base SDXL y que también necesitaremos
- Haga clic en la X parte superior derecha para cerrar la biblioteca de modelos
Stable Diffusion XL ya está disponible en tu espacio de trabajo de Diffus y puedes utilizarlo para crear imágenes.
Creación de una imagen con SDXL
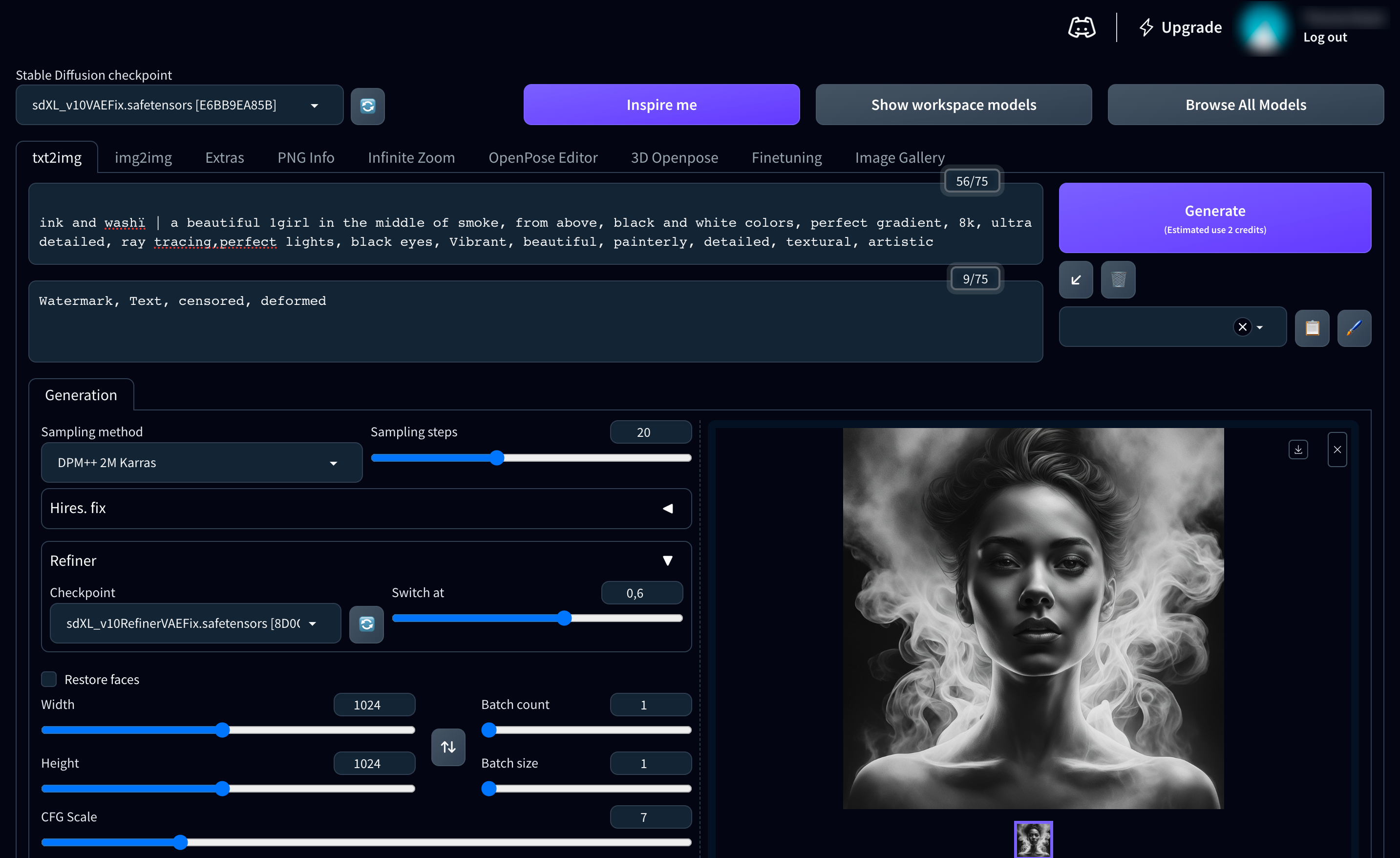
Para generar tu primera imagen con SDXL en Diffus, empieza seleccionando el sdXL_v10VAEFix que acabamos de añadir al espacio de trabajo. Para ello, abre el menú desplegable Stable Diffusion checkpoint en la parte superior izquierda y elige SDXL.
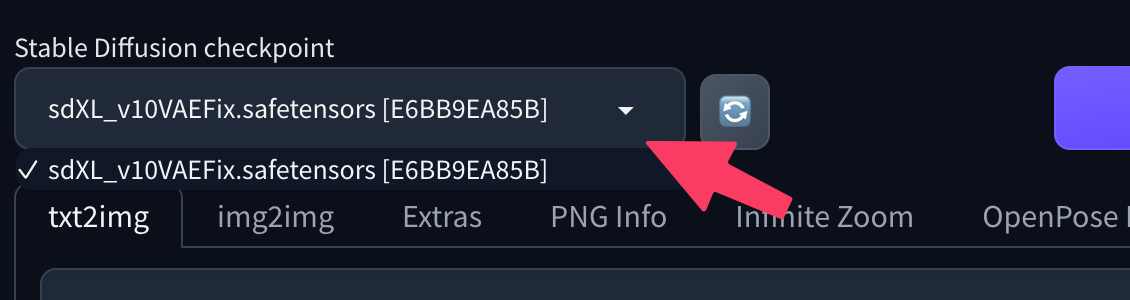
Una vez seleccionado el modelo, siga estos pasos:
- Introduzca una descripción (en inglés) de su imagen en el campo prompt
- Abra el menú Style (a la derecha, bajo el botón Generar) y elija uno de los estilos bajo el encabezado Styles SDXL.
- A continuación, haga clic en Refiner en la pestaña Generation y elija el punto de control sdXL_v10RefinerVAEFix
- A continuación, establece las dimensiones de tus imágenes en 1024x1024.
- Por último, haga clic en el botón Generate
- Su imagen se generará en cuestión de segundos.
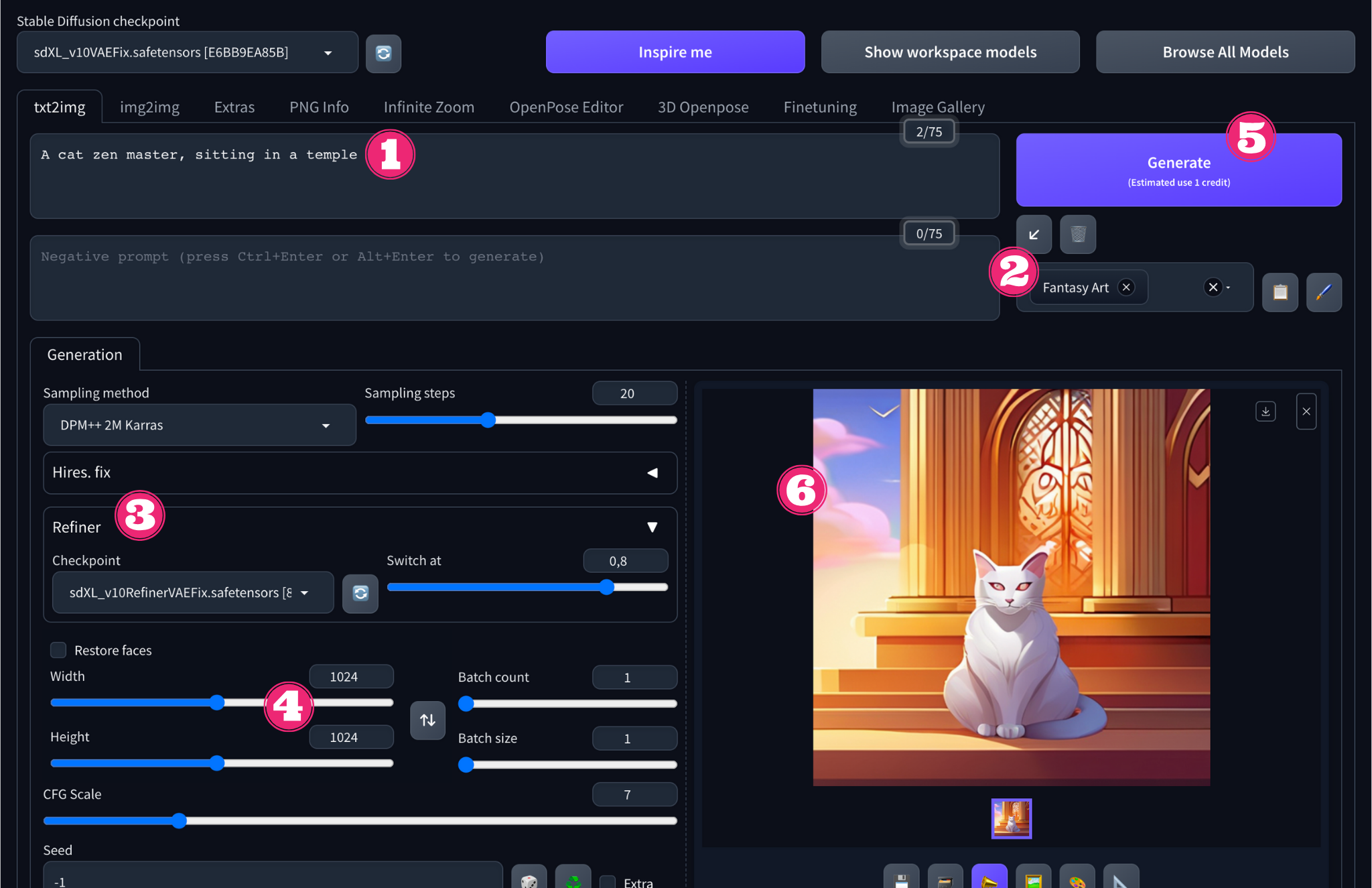
Estos pasos le permiten utilizar la funcionalidad básica de texto a imagen de Stable Diffusion con Automatic1111 en Diffus, pero puede hacer mucho más.
Consulta el manual de Automatic1111 para aprender a utilizar la interfaz gráfica disponible en Diffus, y navega por nuestros artículos para aprender técnicas avanzadas.
Estilos SDXL
En Clipdrop o en el Discord oficial, Stable Diffusion XL dispone de Estilos como Cinemático, Anime o Pixel Art que completan el aviso para generar imágenes en determinados estilos o géneros
Automatic1111 tiene una función similar, que te permite definir tus propios estilos y utilizarlos a través del pequeño menú situado bajo el botón de generar. Tu espacio Diffus viene con una serie de estilos predefinidos - incluyendo los Estilos SDXL de Stability AI, que por lo tanto están optimizados para la última versión de Stable Diffusion
Características del difusor
Si te fijas bien, verás que Diffus utiliza una versión ligeramente modificada de la interfaz de Automatic1111, con algunas características específicas de su alojamiento en la nube.
Bibliotecas modelo
Como vimos cuando añadimos SDXL, tu cuenta de Diffus tiene acceso a una amplia biblioteca de modelos que puedes añadir a tu espacio Diffus para crear con ellos. Para acceder a ellos, sólo tienes que hacer clic en el botón Browse all Models en parte superior derecha de la pantalla
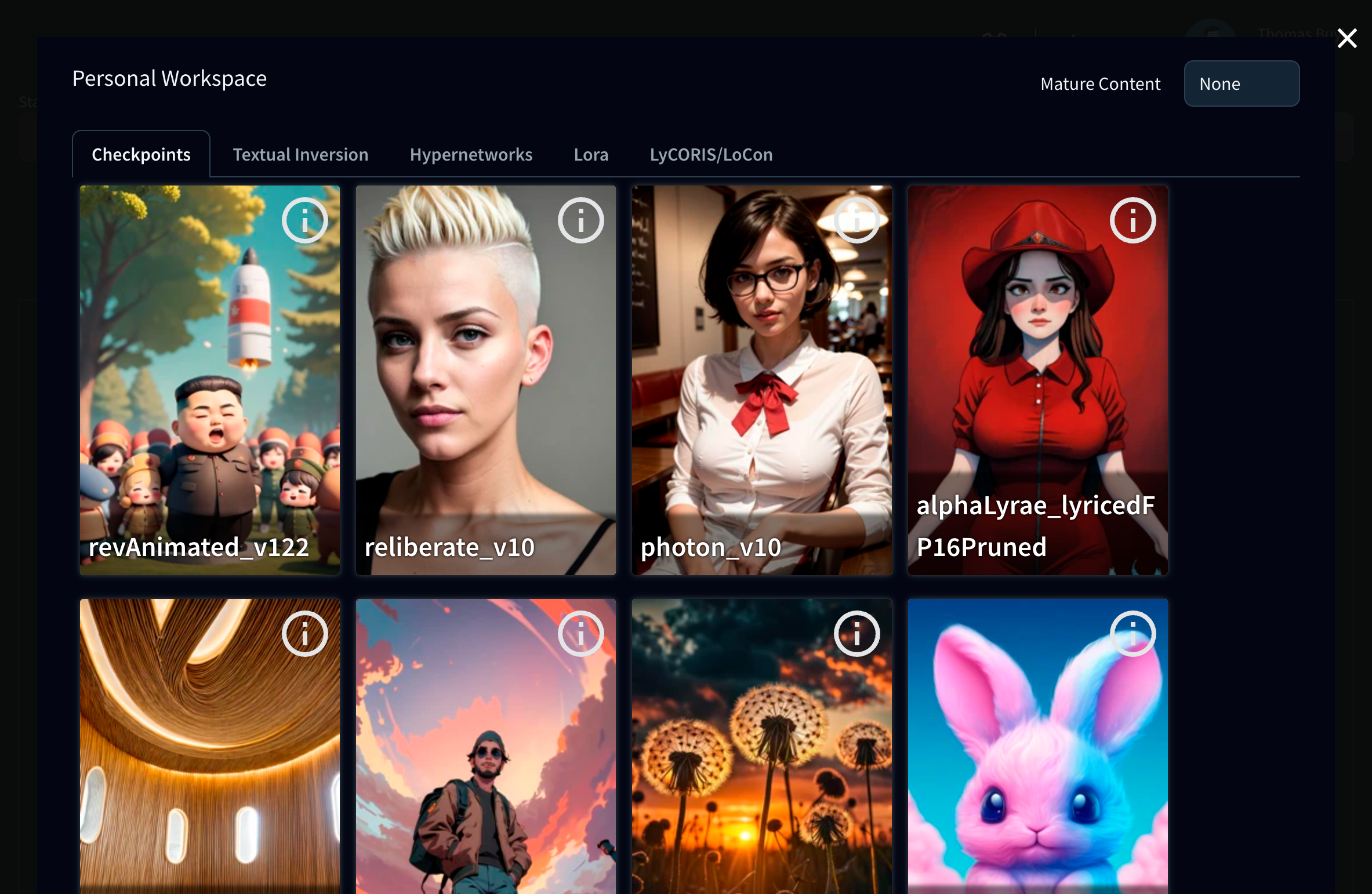
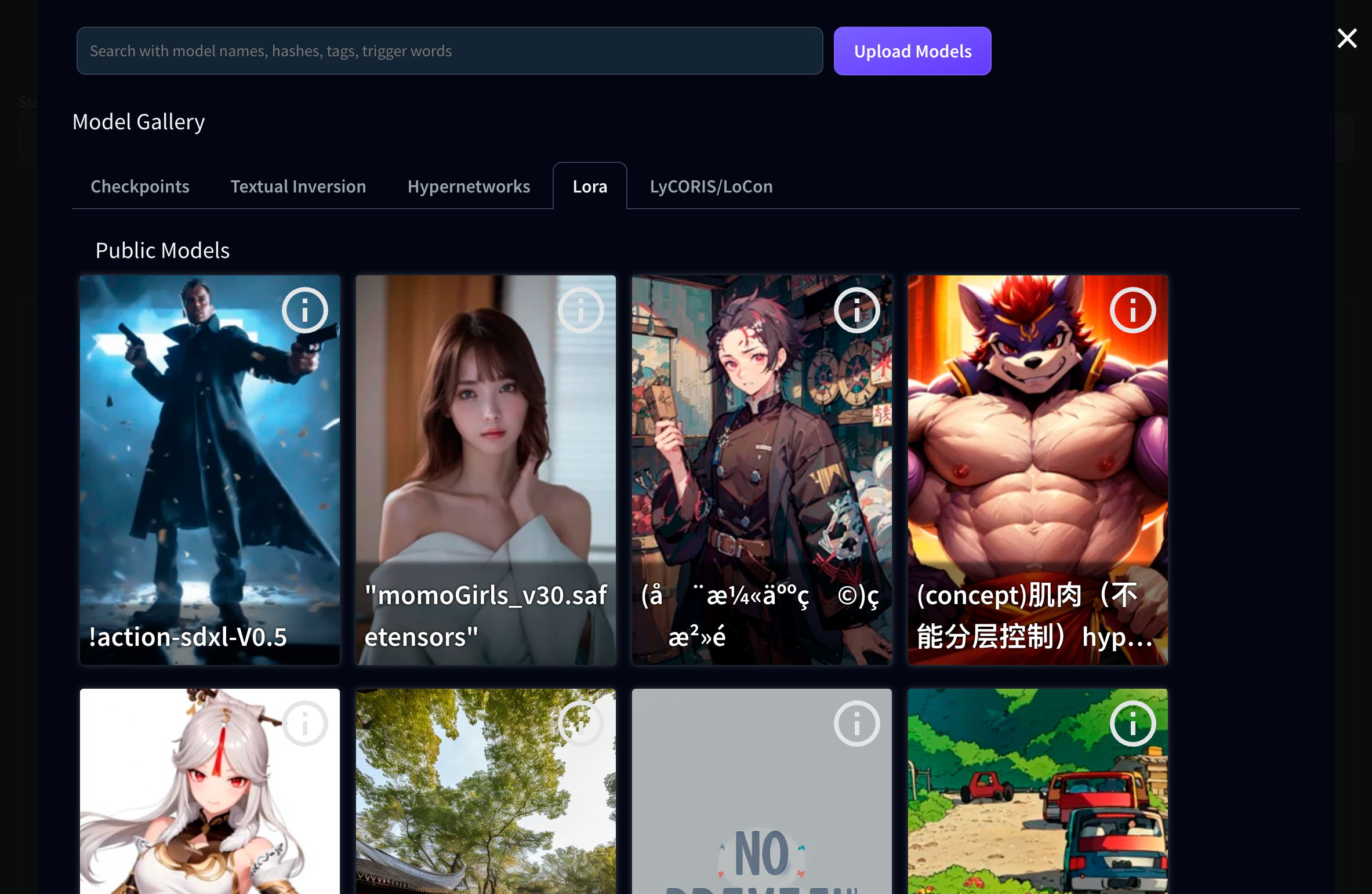
En Diffus, los modelos pueden ser de distintos tipos:
- Checkpoints: a veces también se denominan simplemente Modelos - son una especie de versiones alternativas de Stable Diffusion, entrenadas con un conjunto de datos completo y que pueden dar resultados muy diferentes
- Textual inversions: este tipo de modelo se crea proporcionando una serie de imágenes correspondientes a un concepto y asociándoles una nueva palabra clave. La palabra clave se convierte entonces en una especie de atajo que puede utilizarse en el prompt para describir el concepto en una sola palabra
- Hypernetwork: En Stable Diffusion, la hypernetwork es una capa adicional que se procesa después de que el modelo principal haya renderizado una imagen y que redirige los resultados del modelo según sus datos originales
- LoRA : hasta la fecha, es la forma más popular de añadir datos de entrenamiento específicos a un punto de control inicial para introducir nuevos conceptos (personajes, estilos, poses, etc.)
- LyCORIS/LoCon: esencialmente lo mismo que LoRA, con técnicas de entrenamiento ligeramente diferentes pero un resultado muy similar
Todos estos tipos de modelos pueden utilizarse en Diffus, que ofrece una gama muy amplia en su biblioteca. Añádelas a tu espacio de trabajo haciendo clic en Add to Workspace cuando pases el ratón por encima de una plantilla
También puede obtener información sobre el modelo haciendo clic en el icono de Information (la i dentro de un círculo) que aparece en la parte superior derecha de la imagen del modelo cuando pasa el ratón por encima
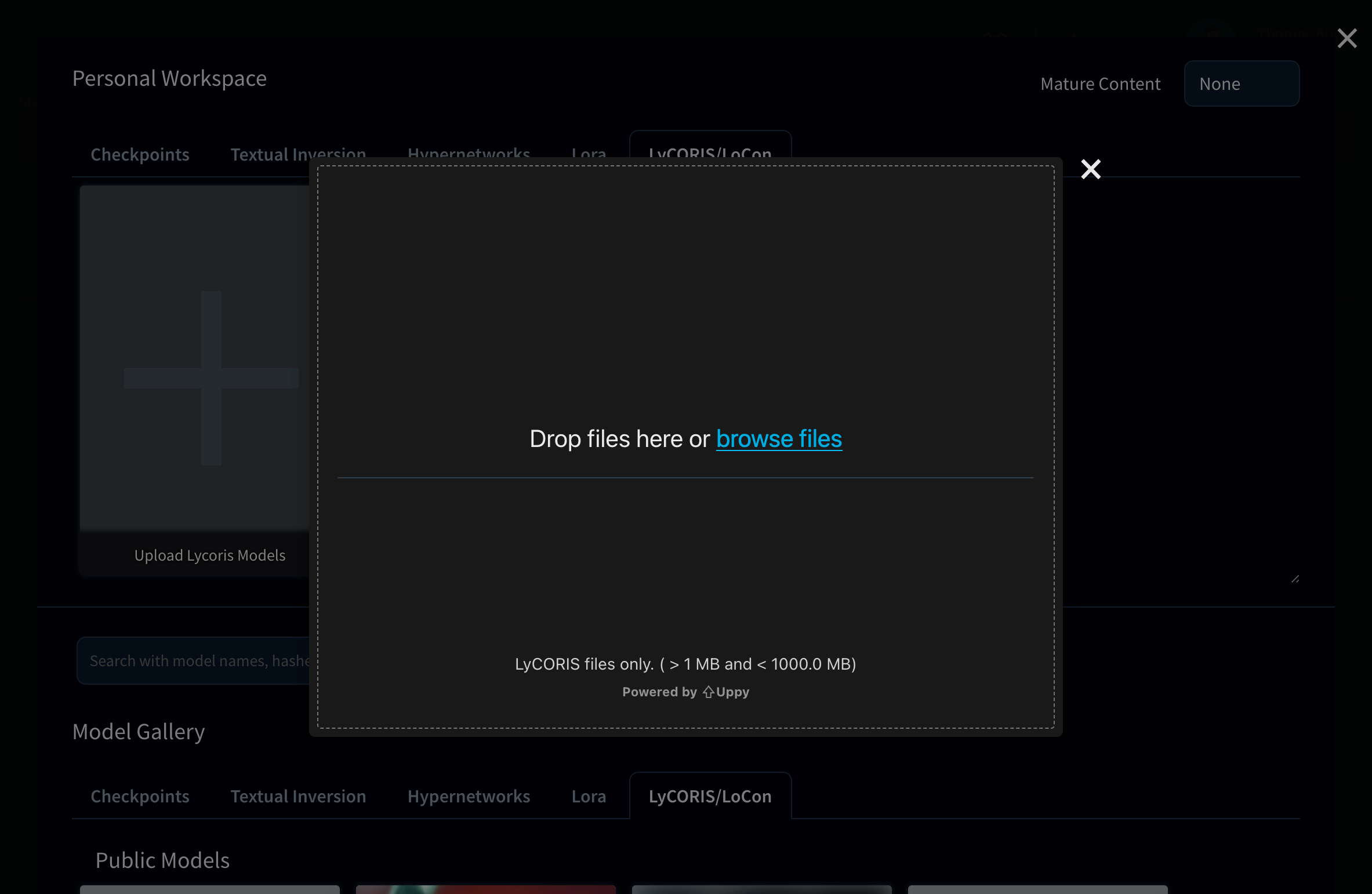
Descargue sus propios modelos
Además de la biblioteca Diffus, también puede añadir sus propias modelos.
Sólo tienes que hacer clic en el botón Upload Models situado junto a la barra de búsqueda, y podrás seleccionar un archivo o añadirlo soltándolo en la ventana de carga
Una vez cargada el modelo en Diffus, se añadirá a su espacio de trabajo.
Utilización de modelos
Aparte del checkpoint, que debe seleccionarse, pueden utilizarse todos los tipos de modelos añadiendo palabras clave o expresiones especiales a la solicitud de generación de imágenes. Esto significa, en particular, que estas otras modelos pueden combinarse normalmente
Además, sól es necesario añadir checkpoints para poder seleccionarlos y utilizarlos en Diffus. Todos los demás tipos de modelos pueden utilizarse directamente sin añadirlos al workspace si se conoce la palabra clave que hay que utilizar
Sin embargo, recordar todas las palabras clave que hay que utilizar para activar las plantillas no es fácil, y aquí es donde resulta útil la incorporación al espacio de trabajo, que permite activar las plantillas con unos simples clics.
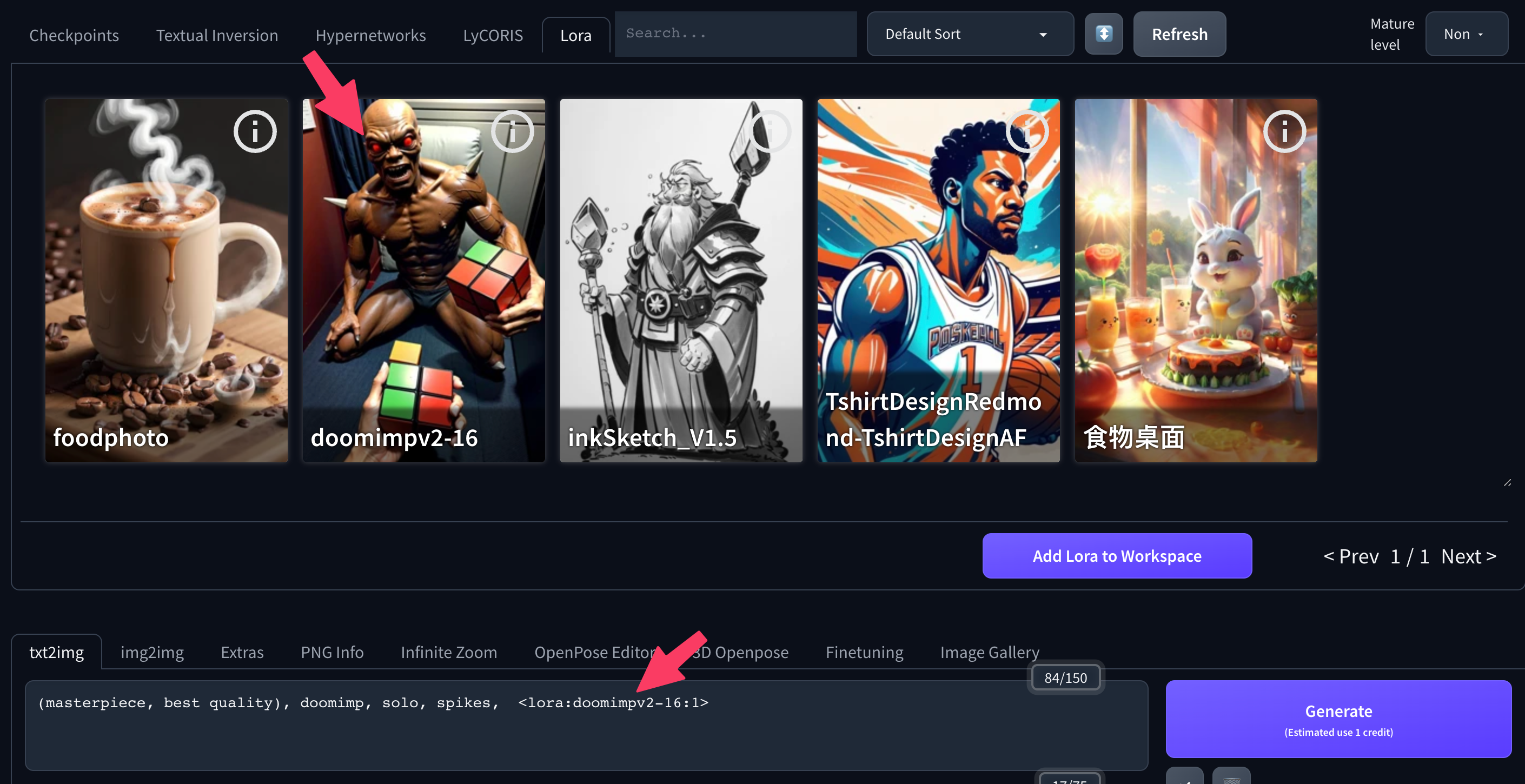
Una vez añadido el modelo a su workspace, puede encontrarlo fácilmente haciendo clic en Show workspace models, lo que mostrará una lista de sus modelos. A continuación, puede seleccionar un modelo haciendo clic en él, lo que añadirá automáticamente la palabra clave correspondiente a su prompt.
Galería de imágenes
Diffus también ha añadido una pestaña Image Galery la interfaz de Automatic1111, que da acceso a la galería de imágenes que has generado con Diffus y a su historial
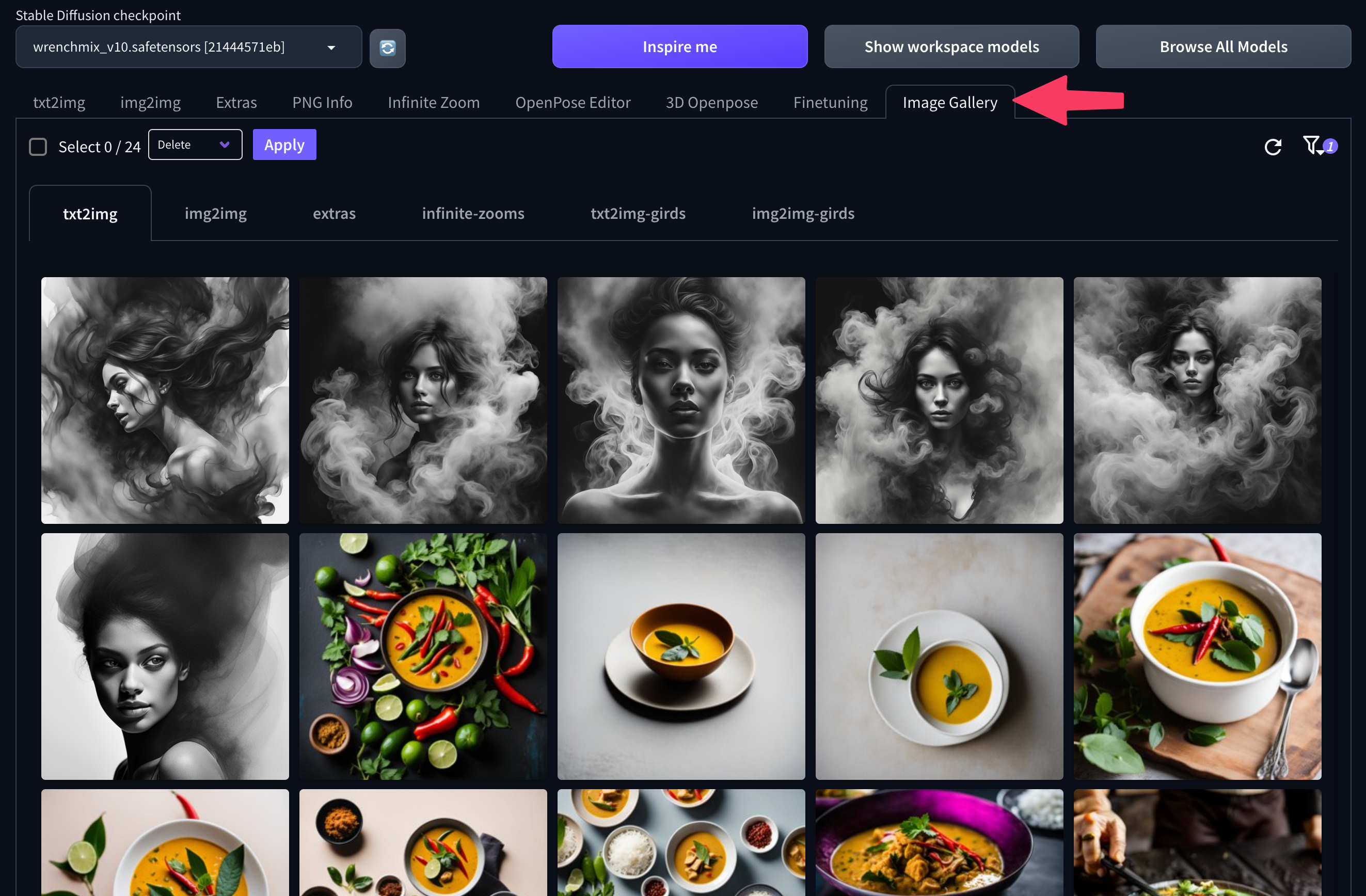
Tus imágenes se almacenan en la nube de Diffus y se organizan en colecciones en función de la pestaña desde la que se generaron. Así, las imágenes creadas mediante text-to-image estarán disponibles en txt2img mientras que las animaciones creadas mediante la extensión Infinite Zooms se almacenarán en la pestaña del mismo.
Detalles de la imagen
Haz clic en una imagen para ampliarla y ver los detalles de su generación. También puedes realizar varias acciones a partir de tu imagen:
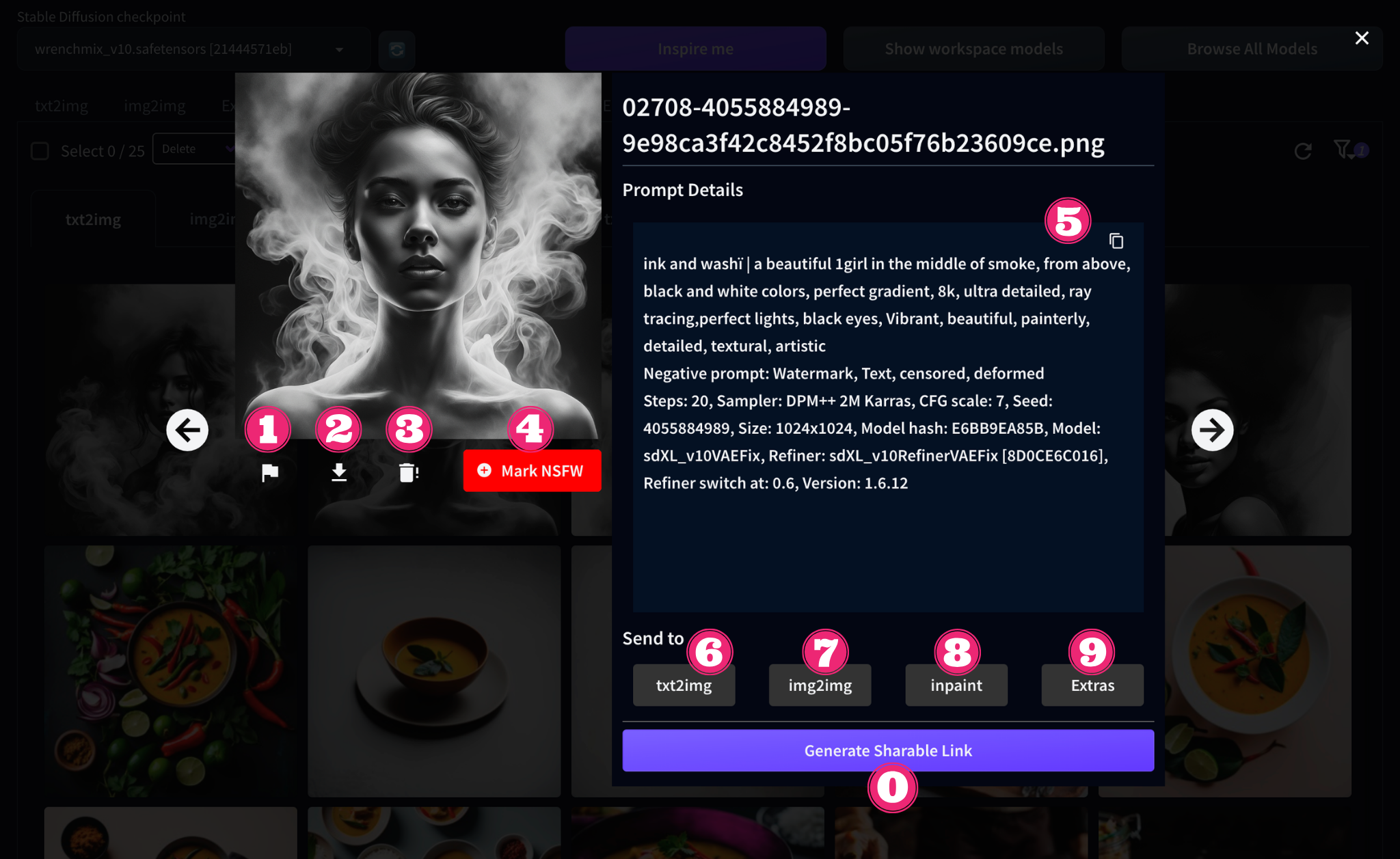
Hay 4 botones disponibles debajo de la miniatura de la imagen:
- La banderita añadir la imagen a tus Favoritos
- El icono de descarga permite, lógicamente descargar la imagen.
- Utiliza el pequeño cubo de basura para borrar la imagen por completo de la nube Diffus
- Este botón rojo marcar una imagen como NSFW
- Derecha de la imagen, los datos de generación aparecen en forma de texto. El pequeño icono situado en la parte superior derecha de este texto le copiar estos datos.
- Bajo los datos de generación, dispone de 4 accesos directos que le permiten utilizar la imagen para una nueva generación. text2img abre la pestaña del mismo nombre para una generación text-to-image que incluye el prompt de la imagen, su seed y sus distintos parámetros de generación (dimensiones, steps, cfg)
- img2img abre la imagen en la pestaña image-to-image, por ejemplo para crear una variación
- inpaint también abre la pestaña imagen-a-imagen, pero preselecciona los elementos de configuración para el inpainting.
- Extra abre la imagen en la pestaña del mismo
- Por último, el botón Generate Sharable Link crea un enlace como este para compartir fácilmente tu imagen. Una vez creado el enlace, el botón se sustituye por una serie de botones para utilizar el enlace directamente en varias redes como 𝕏, Whatsapp o Telegram

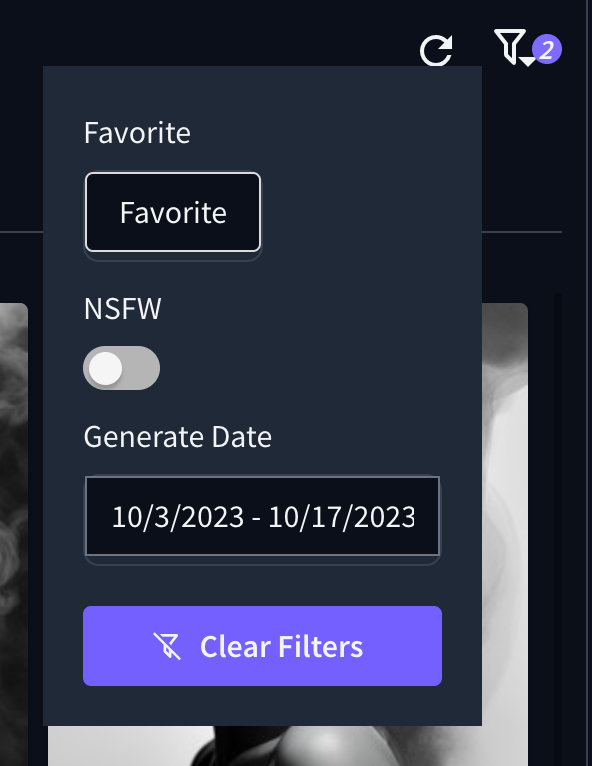
Filtrar colecciones
En la esquina superior derecha, puede utilizar un filtro de búsqueda para buscar entre las imágenes de la colección mostrada. Aquí puede establecer el periodo para la fecha de creación de la imagen y mostrar sólo las imágenes que son favoritas y/o están marcadas como NSFW.
Los filtros se aplican automáticamente, y el botón Borrar filtros permite desactivarlos todos con un solo clic
Modo Boost
Los suscriptores de Diffus pueden activar una opción adicional, Boost, para generar sus imágenes más rápidamente.
El principio básico de una nube como Diffus es utilizar recursos compartidos entre los usuarios, lo que les permite mantener bajos los costes de uso aprovechando al máximo los servidores y GPU de que disponen.
Pero el inconveniente de los recursos compartidos es que a veces hay que esperar turno para utilizarlos. En Diffus, las peticiones de generación se ponen en cola (queue) antes de asignarse realmente a una GPU, y esta cola puede tardar varios (largos) segundos... ¡o incluso más!
Para los usuarios con prisa, o los que quieren avanzar rápidamente en un proyecto, Diffus ha introducido una opción que permitelos usuarios beneficiarse de una GPU dedicada Al activar Boost ya no hay que compartir ni esperar, y la generación se vuelve mucho más rápida.
Es como usar Automatic1111 en tu propia máquina, pero en la nube (y con una GPU optimizada).
¿Cómo se utiliza Boost?
Para activar esta opción, primero debe adquirir horas Boost:
- Haga clic en la flecha hacia abajo situada a la derecha del botón Activate Boost para ver los tiempos de boost disponibles
- en Haga clic en Click to Purchase More para abrir la página de pago
- Elige el número de horas y paga con Stripe.
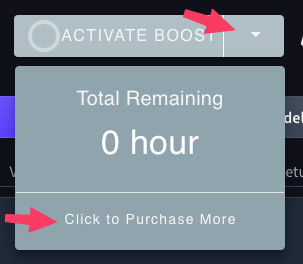
Una vez que dispongas de horas Boost, sólo tienes que hacer clic en el botón para iniciar una sesión en modo Boost. A continuación, Diffus prepara tu GPU dedicada, carga tus modelos en ella e inicia la sesión en unos minutos.
Una sesión dura un mínimo de 30 minutos y puede prolongarse tanto como desee.
Al escribir estas líneas, el Boost disponible por 3 $/hora -es decir, 1,5 $ por una sesión de 30 minutos- y Diffus también ofrece hasta 5 horas de Boost gratis con los paquetes de suscripción más altos.
Créditos y suscripciones
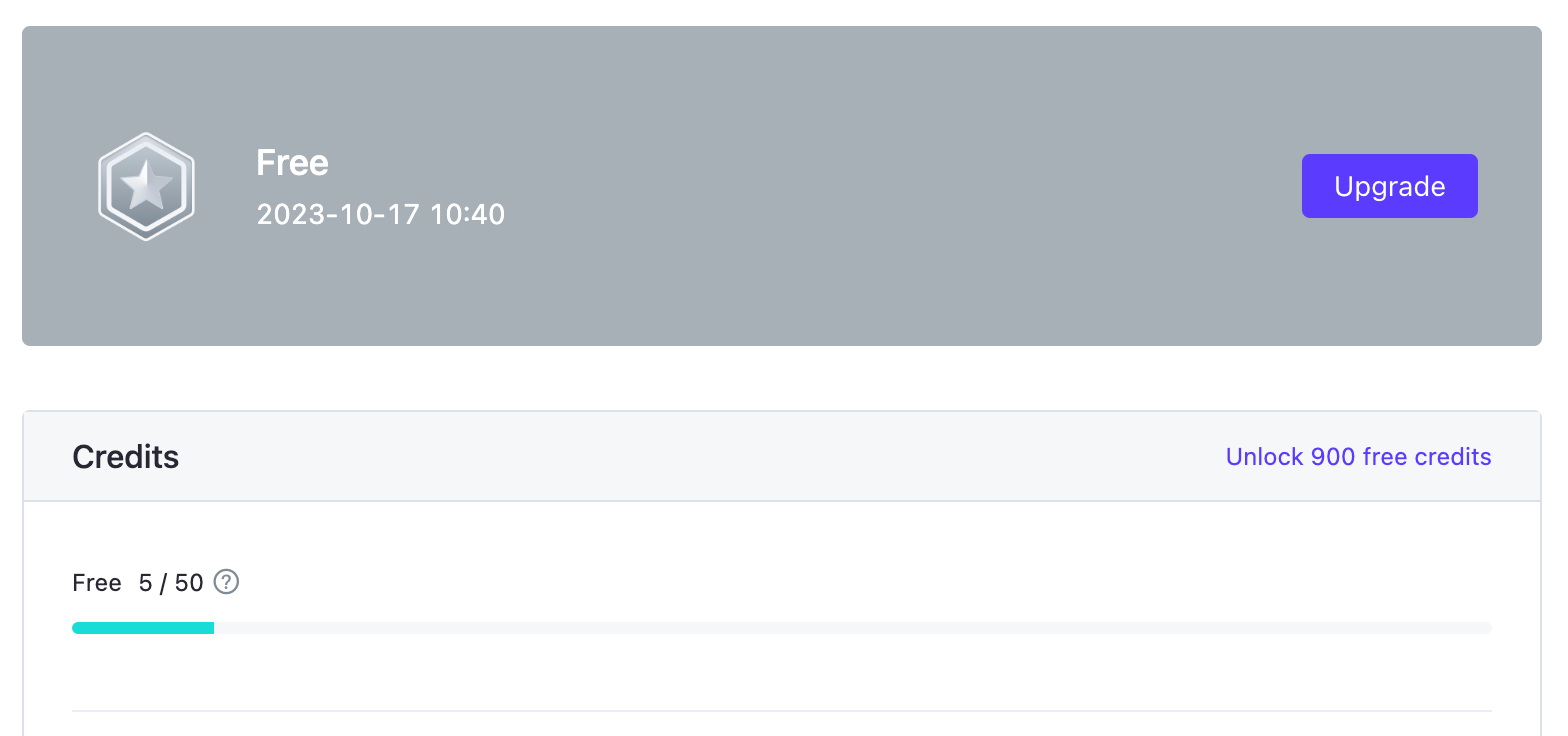
¿Diffus es gratuito?
No. Desde abril de 2024, Diffus ya no ofrece una fórmula totalmente gratuita.
Aunque crear una cuenta es gratis, tendrás que suscribirte (por sol 1 euro al mes) para utilizar la interfaz web y crear tus imágenes.
El número de imágenes que puedes crear al día depende de tu suscripción.
Diffus funciona con un sistema de créditos: cada imagen cuesta uno o más créditos, según su complejidad.
El paquete de prueba de 1 euro al mes, por ejemplo, da derecho a 30 créditos diarios.
Existen varias fórmulas de suscripción que le permiten beneficiarse de créditos mensuales adicionales.
También existe una técnica para obtener hasta 50 créditos extra al día.
¿Cuántas imágenes puedo crear con 30 créditos diarios?
En la práctica, una imagen de 512x512 generada con Stable Diffusion 1.5 cuesta 1 crédito, mientras que una imagen de 1024x1024 generada con SDXL cuesta 2 créditos.
Con 30 créditos, puede generar entre 15 y 30 imágenes, en función de la resolución requerida.
Suscripciones Diffus
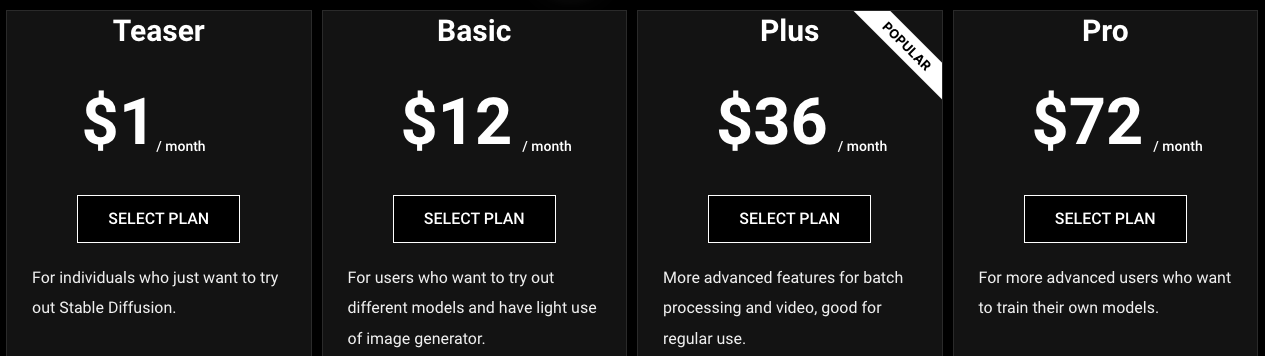
Diffus ofrece 3 paquetes de suscripción, cuyos precios aumentan en función del número de créditos.
El primer paquete cuesta 12 euros al mes por 5.000 créditos (Basic), más créditos diarios (hasta 50 al día). Los siguientes paquetes cuestan 36 euros por 18.000 créditos mensuales (Plus) y 72 euros por 40.000 créditos (Pro). Todas las suscripciones están disponibles como paquetes mensuales o anuales, con una promoción 12 meses por el precio de 10
Ventajas de la suscripción
Además de los créditos mensuales que permiten generar más imágenes, las suscripciones a Diffus ofrecen otras ventajas como :
- Acceso prioritario a los recursos del servidor para una generación más rápida.
- Acceso a extensiones de animación y generación de vídeo.
- Acceso a funciones avanzadas de scripting X/Y en Automatic1111
- Espacio de almacenamiento privado adicional imágenes y vídeos creados con Diffus
- Puedes mantener tus imágenes 100% privadas.
- Capacidad para crear y entrenar sus propios modelos de ajuste (LoRA, Textual Inversion e Hypernetwork)
- Espacioalmacenamiento para los datos de formación
- Horas libres de Boost
Gana 50 créditos extra al día
Diffus recompensa a los usuarios habituales con créditos diarios gratuitos. He aquí cómo conseguir esos créditos extra:
- Pulsa ⚡Upgrade junto a tu nombre, arriba a la derecha
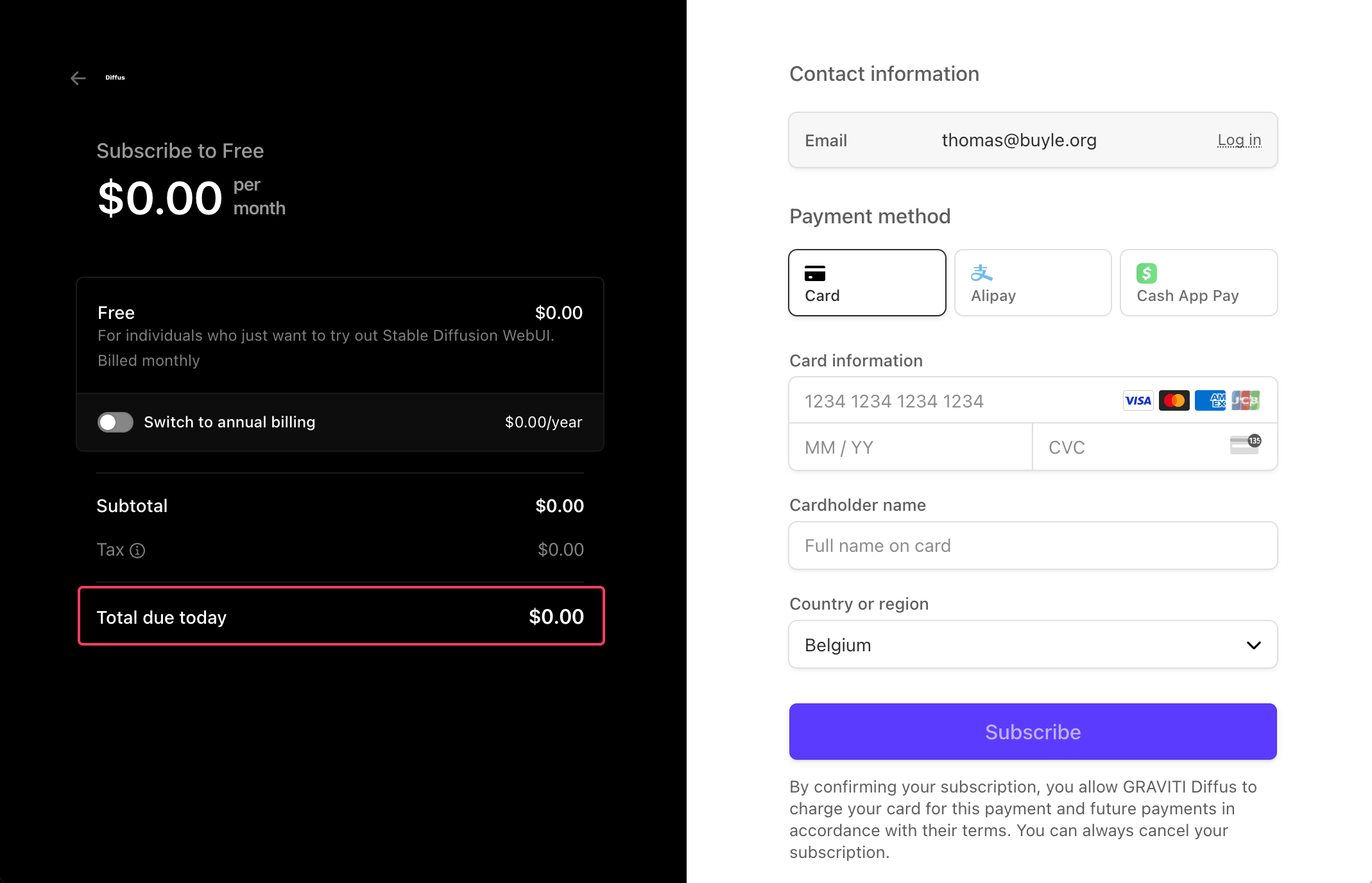
- en el botón Subscribe de la primera columna para elegir el paquete de 1 euro al mes
- Introduzca sus datos de pago
- Confirme su inscripción haciendo clic en Subscribe
- Ahora hay disponible un enlace 📅 Check-In junto al enlace ⚡Upgrade haz clic en él para obtener tus créditos gratuitos del día
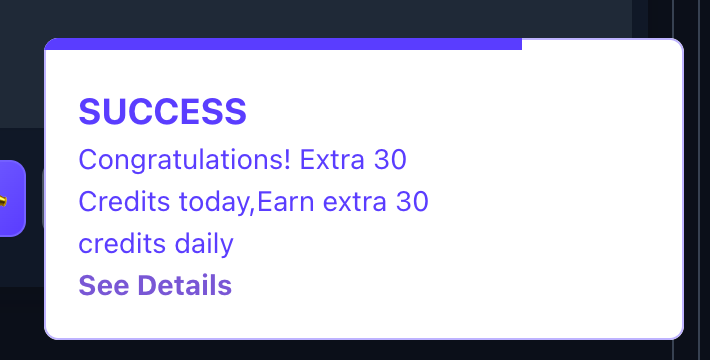
El primer día que hagas clic en Check-In, obtendrás 5 créditos extra para ese día. Después, cada día consecutivo hagas check-in obtendrás 5 créditos gratis más que el día anterior, hasta un máximo de 30 créditos extra después de 6 días seguidos, lo que te dará 50 créditos diarios gratis.
Nota: Si un día para registrarte, el contador se reiniciará con 5 créditos la próxima vez que te conectes Así que no olvides visitar el sitio, incluso los días en que no tengas previsto crear nada con Stable Diffusion
No espere más, pruebe Diffus
Su bajo coste y su facilidad de uso hacen Diffus solución ideal para que pruebes a generar imágenes basadas en IA. En sólo unos minutos, estarás listo para dar tus primeros pasos con Stable Diffusion y dar rienda suelta a tu creatividad creando nuevas imágenes
Written by

