
Table of Contents
- Los distintos tipos de modelos
- Modelos básicos
- Modelos afinados (finetuned)
- ¿Qué es el fine-tuning?
- ¿Por qué se crean?
- ¿Cómo se crean?
- Los principales modelos de Stable Diffusion
- Modelos básicos
- Stable Diffusion 3
- 🔥 Stable Diffusion XL
- SDXL Turbo
- Stable Diffusion 2.0 y 2.1
- Stable Diffusion 1.5
- Stable Diffusion 1.4
- Modelos afinados
- Copax TimeLessXL (SDXL)
- blue_pencil-XL (SDXL)
- DynaVision XL (SDXL)
- Open Journey (SD 1.5)
- Anything V3 (SD 1.5)
- Arcane Diffusion (SD 1.5)
- Woolitize Diffusion (SD 1.5)
- Dreamshaper (SD 1.5)
- Deliberate (SD 1.5)
- ¿Dónde puedo encontrar más modelos?
- ¿Cómo se utilizan estos modelos?

Do not index
canonical-url
Publish
Publish
Flag
Las modelos, también conocidas como checkpoints, son archivos creados por Stable Diffusion utilizando imágenes específicas.
Estos modelos pueden adaptarse a un estilo, género o tema concretos, pero también existen modelos genéricos capaces de generar todo tipo de imágenes. Lo que los modelos pueden generar depende, por tanto, de los datos utilizados para entrenarlos: las imágenes y los textos asociados a ellas determinarán lo que el modelo puede representar y las palabras clave que reconocerá.
Los distintos tipos de modelos
Modelos básicos
Estos son los principales modelos utilizados por Stable Diffusion, creados a partir de un gran número de imágenes y que constituyen la base de nuestra capacidad de creación de imágenes.
Como estas modelos requieren una gran cantidad de imágenes para su creación, no existen muchas diferentes, siendo las más conocidas las publicadas por la empresa creadora de Stable Diffusion: Stablity AI - de hecho, es a estas modelos a las que se suele hacer referencia cuando se habla de Stable Diffusion.
Actualmente existen 6 modelos básicos: 1.4, 1.5, 2.0 y 2.1, SDXL, SDXL Turbo y 3. Entraremos en más detalles más adelante en este artículo, pero debes saber que hay diferencias importantes entre cada generación.
Modelos afinados (finetuned)
¿Qué es el fine-tuning?
El fine-tuning es una técnica común en el aprendizaje automático que consiste en tomar un modelo que ya ha sido entrenado en un gran conjunto de datos y entrenarlo un poco más en un conjunto de datos específico.
Por tanto, un modelo ajustado estará "sesgado" hacia la generación de imágenes similares a las utilizadas para este entrenamiento, al tiempo que conserva la versatilidad del modelo original.
¿Por qué se crean?
Los modelos básicos de Stable Diffusion son excelentes, pero no sirven para todo.
Por ejemplo, pueden generar imágenes de estilo manga o anime con la palabra clave "anime" en el prompt. Pero es más difícil utilizarlas eficazmente para los subgéneros del anime (chibbi, shonen, kodomo). En lugar de perder tiempo ajustando complejos prompts para casos tan específicos, puedes afinar la modelo con imágenes para estos subgéneros.
Del mismo modo, los modelos básicos resultan familiares para muchas celebridades y personajes estadounidenses o mundialmente conocidos, como Ryan Reynolds o Harry Potter, pero suelen ser menos eficaces para celebridades más locales, como Buenafuente, o ficciones menos populares. Se puede recurrir al fine)tuning fina para "enseñarles" quiénes son estos personajes.
¿Cómo se crean?
Existen cuatro métodos principales de ajuste: formación adicional, Dreambooth, inversión de texto y LoRAs, todos ellos basados en un modelo básico de Stable Diffusion como 1.5 o SDXL.
- entrenamiento adicional se consigue entrenando un modelo base con un conjunto de datos adicional de interés. Por ejemplo, podría entrenar Stable Diffusion v1.5 con un conjunto de datos adicional de coches antiguos para sesgar la estética de los coches hacia el subgénero. Este entrenamiento genera un nuevo modelo en forma de Checkpoint. Es esencialmente este tipo de ajuste del que hablaremos en el resto de este artículo.
- Dreambooth es una técnica desarrollada originalmente por Google que permite inyectar temas personalizados en modelos de text-to-image. Funciona con tan sólo entre 3 y 5 imágenes personalizadas. Este método se popularizó muy rápidamente porque permitió crear los primeros servicios para crear avatares personalizados con IA: puedes hacerte unas cuantas fotos y utilizar Dreambooth para insertarte en la modelo. Su principal inconveniente es que, al añadir nuevos datos a la modelo existente, el archivo de control resultante puede llegar a ser muy grande (5 Gb o más).
- Una otra técnica de ajuste más reciente es la llamada inversión textual (textuel inversion en Ingles - también llamada embedding). El objetivo es similar al de Dreambooth: inyectar un tema personalizado en la modelo con sólo unos ejemplos, para lo cual se crea una palabra clave nueva y única. Con este método, sólo se ajusta la parte textual de la modelo, manteniendo el resto de la modelo sin cambios. En otras palabras, enseña a la modelo el significado de una palabra nueva, sin modificar los conceptos visuales que ya conoce. Su gran ventaja es que genera archivos complementarios a la propia modelo, mucho más ligeros de intercambiar y que, en algunos casos, pueden funcionar con modelos distintas de la original.
- LoRA (de Low-Rank Adaptation) o adaptación de bajo rango, una técnica matemática que se utiliza para reducir el número de parámetros que hay que entrenar cuando se afinan los modelos. Funciona creando una diferencia de modelo en lugar de guardar el modelo completo. Los archivos LoRA son, por tanto, aún más pequeños y fáciles de intercambiar que los archivos incrustación
Este artículo, sin embargo, está dedicado a los ficheros de checkpoints, que se denominan simplemente modelos. Los ficheros de inversión textual y los LoRA son casos diferentes que no se utilizan de la misma manera, y los trataremos en otros artículos.
Para más información sobre los LoRAs y cómo utilizarlos, consulte nuestra Guía de los LoRAs.
Los principales modelos de Stable Diffusion
Modelos básicos
Stable Diffusion 3

Stable Diffusion 3 es el último modelo de generación de imágenes diseñado por Stability AI.
No se trata de un único modelo, sino de una serie de modelos que varían considerablemente de tamaño. La gama abarca desde 800 millones hasta 8.000 millones de parámetros.
Consulte la Guía de Stable Diffusion 3 para saber todo lo que necesita saber sobre esta serie de modelos.
🔥 Stable Diffusion XL

Stable Diffusion XL o SDXL es el último modelo de generación de imágenes diseñado para producir resultados más fotorrealistas con imágenes y composiciones más detalladas que los modelos anteriores, incluida la versión 2.1.
Con Stable Diffusion XL, puede crear imágenes más realistas con una mejor generación de caras, producir texto legible dentro de las imágenes y lograr resultados estéticamente más agradables utilizando indicaciones más cortas.
SDXL Turbo
SDXL turbo es una versión de SDXL optimizada para generar imágenes mucho más rápido.
El resultado es un modelo capaz de generar imágenes en tiempo real, o muy próximo a él, con una calidad muy próxima a la del modelo original (SDXL). Su utilización requiere ajustes precisos, ligeramente diferentes de los utilizados para los modelos estándar.
Consulta la Guía SDXL Turbo para averiguar todo lo que necesitas saber sobre SDXL Turbo y cómo utilizarlo
Stable Diffusion 2.0 y 2.1

Tras Stable Diffusion 1.5, Stability AI ha lanzado una nueva serie de modelos de segunda generación. Se han lanzado los modelos 2.0 y 2.1. Los principales cambios de los modelos v2 son los siguientes:
- Además de 512×512 píxeles, existe una versión de mayor resolución 768×768 píxeles
- Las imágenes pornográficas o eróticas se han eliminado del entrenamiento, por lo que ya no es posible generar imágenes explícitas.
Uno pensaría que todo el mundo se habría pasado a los modelos de segunda generación en cuanto salieron, pero la comunidad de usuarios de Stable Diffusion descubrió que las imágenes eran a menudo de peor calidad en el modelo 2.0, en gran parte porque las palabras clave que se habían hecho comunes gracias a prompt engineering, como los nombres de famosos y artistas, no funcionan en este modelo
El modelo 2.1 ha resuelto parcialmente estos problemas. Las imágenes se ven mejor desde el principio y es más fácil generar un estilo artístico con ellas. Sin embargo, la mayoría de la gente no ha abandonado por completo los modelos de la primera generación. Muchos utilizaban el 2.1 ocasionalmente, pero pasaban la mayor parte del tiempo con los modelos de la primera generación.
Stable Diffusion 1.5
.png)
La versión 1.5 fue lanzada en octubre de 2022 por Runway ML, socio de Stability AI, y se basa en la versión privada 1.2 con entrenamiento adicional.
La presentación no menciona realmente en qué consiste la mejora. Produce resultados ligeramente diferentes en comparación con la versión 1.4, pero no siempre son mejores. Al igual que la versión 1.4, se puede considerar que la 1.5 es un modelo versátil.
Es una buena elección como modelo inicial que puede utilizarse prácticamente de forma intercambiable con el 1.4.

Para comparar los resultados entre las versiones 1.4 y 1.5, vea este vídeo de youtube (con subtítulos en espanol)
Stable Diffusion 1.4

Publicado en agosto de 2022 por Stability AI, el modelo 1.4 se considera el primer modelo público de Stable Diffusion.
Es un modelo de uso general y la mayoría de las veces puedes utilizarlo tal cual para crear imágenes de calidad.
Modelos afinados
Copax TimeLessXL (SDXL)

TimeLessXS es un modelo genérico capaz de crear imágenes de diversos tipos y estilos, pero con cierta predilección por las imágenes realistas o fotorrealistas.
blue_pencil-XL (SDXL)

Esta modelo es una amalgama de una serie de otras modelos SDXL que dan resultados interesantes, sobre todo para generar ilustraciones de estilo anime.
DynaVision XL (SDXL)

DynaVision XL es un modelo formado a partir de una serie de imágenes fotorrealistas, que luego se fusionan con otros modelos y LoRA para conseguir un renderizado similar a una animación 3D, similar al trabajo de estudios como Pixar o Dreamworks.
Open Journey (SD 1.5)

Open Journey es una modelo perfeccionada por PromptHero con imágenes generadas por Midjourney v4, otra IA de generación de imágenes. Tiene una estética diferente y es una buena modelo completa en un estilo de arte esencialmente digital
Las imágenes de Midjourney son muy populares por su estética, pero esta IA sólo está disponible a través de Discord y hay que pagar por ella. Openjourney es una alternativa gratuita que utiliza imágenes generadas previamente con Midjourney .
Nota: para aprovechar al máximo esta modelo, debe activarla añadiendo la palabra clave
mdjrny-v4 style al principio de la solicitudAnything V3 (SD 1.5)

Anything V3 es una modelo especializada diseñada para producir imágenes de estilo anime de alta calidad. Se ha entrenado con descripciones que utilizan etiquetas danbooru (como 1girl, pelo blanco) y, por lo tanto, pueden utilizarse en prompts.
Es EL modelo para generar imágenes de estilo manga y anime, y se utiliza ampliamente a pesar del misterio que rodea su creación (todo lo que sabemos es que procede de China) y su tendencia a generar personajes femeninos muy sexualizados.
Arcane Diffusion (SD 1.5)

Arcane Diffusion es un modelo afinado basado en imágenes de serie de Netflix Arcane, que produce imágenes y retratos con el estilo fuerte y estético de esta serie de éxito
Nota: para aprovechar al máximo esta modelo, debes activarla añadiendo la palabra clave
estilo arcano al principio de la instrucciónWoolitize Diffusion (SD 1.5)

Este patrón extrañamente popular está afinado para generar fotos de elementos deshilachados en lana de ganchillo.
Nota: para aprovechar al máximo esta modelo, debe activarla añadiendo la palabra clave
woolitize al principio de la consultaDreamshaper (SD 1.5)

Este modelo se creó en primer lugar para hacer buenos retratos que no parecieran imágenes generadas por ordenador o fotos con muchos filtros, sino más bien pinturas reales. El resultado es un modelo capaz de crear retratos, pero también magníficos paisajes y personajes con un estilo más manga.
Deliberate (SD 1.5)

Esta modelo te da la oportunidad de crear lo que quieras. Cuanto más sepas sobre las instrucciones a dar, mejores resultados obtendrás. Esto significa básicamente que nunca obtendrás un resultado perfecto con unas pocas palabras. Tendrás que crear tus instrucciones con un nivel de detalle bastante extremo para sacar el máximo partido a esta modelo.
¿Dónde puedo encontrar más modelos?
La comunidad de Stable Diffusion comparte en línea un gran número de modelos. Éstos son los dos principales recursos para encontrar nuevas modelos y puntos de control:
- Hugging Face, la mayor comunidad de investigadores, usuarios y creadores de IA, tiene bastantes modelos disponibles, pero no es necesariamente fácil de buscar, sobre todo porque hay modelos para todo tipo de IA diferentes
- Civitai.com totalmente dedicada a la Stable Diffusion y es mucho más fácil buscar nuevos modelos
¿Cómo se utilizan estos modelos?
Cuando instala Stable Diffusion o se ejecuta en un Google Colab, se instala al mismo tiempo un modelo básico, normalmente el modelo 1.5 o SDXL, que están preconfigurados
Dado que recomendamos utilizar la interfaz automática 1111 o la interfaz Fooocus, nos centraremos en esta última y explicaremos cómo utilizar un archivo de modelo con :
Instalación de un modelo de Stable Diffusion en Automatic1111
- Descargue el archivo de puntos de control (idealmente en formato
.safetensors, pero puede ser un.ckpt)
- Coloque el archivo en el directorio
/stable-diffusion-webui/models/Stable-diffusionde su instalación (si utiliza google colab, este directorio se encuentra en el directorio /sd creado en su google drive)
- Lanzamiento automático 1111
- Haz clic en el selector situado en la parte superior izquierda de la interfaz para elegir el modelo.
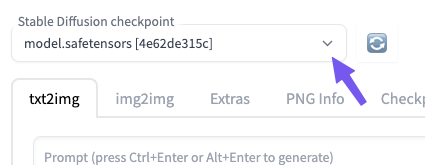
- Espera a que se cargue el modelo.
- Ahora puede utilizar la modelo para generar sus imágenes.
Instalación de un modelo de Stable Diffusion en Fooocus
- Descargue el archivo de puntos de control (idealmente en formato
.safetensors, pero puede ser un.ckpt)
- el archivo en el directorio
/models/checkpointsde su instalación
- Lanzamiento de Fooocus
- Haga clic en Avanzadas debajo del campo de consulta para mostrar las opciones avanzadas y abrir el Modelos en la columna que aparece
- Si es necesario, haga clic en Actualizar todos los archivos en la parte inferior para actualizar la lista de modelos
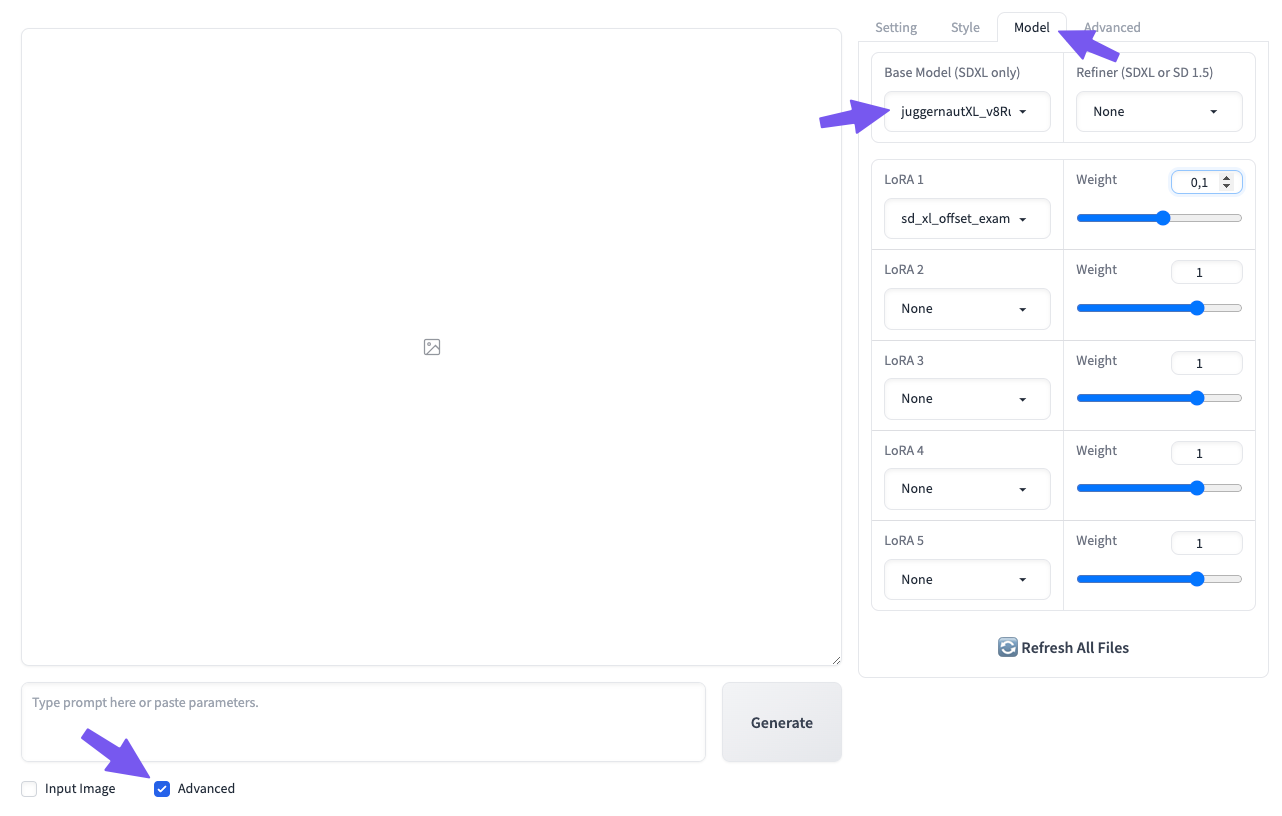
- Ahora puede utilizar la modelo para generar sus imágenes.
Importante: Fooocus sólo puede utilizar puntos de control basados en SDXL; si tu modelo no aparece en la lista, probablemente esté basado en otra versión
Written by


